Виды объектов баз данных Db2
Настоящий раздел содержит обзор видов объектов баз данных Db2. Полный перечень видов объектов баз данных Db2 и детальная информация по каждому виду объектов приведена в документации:
- описание типов данных;
- встроенные функции;
- системный каталог;
- таблицы;
- ограничения целостности;
- индексы;
- триггеры;
- последовательности;
- представления.
Схемы
Схемы – это пространства имён для других объектов базы данных. Схемы преимущественно используются для:
- обеспечения индикации монопольного использования объектов или связей с приложением;
- логической группировки связанных объектов.
Все объекты базы данных Db2 (за исключением публичных синонимов) имеют полностью классифицированные имена, состоящие из двух частей; схема является первой частью такого имени: <имя_схемы>.<имя_объекта>
Полностью классифицированное имя объекта должно быть
уникальным. Если подключиться к базе данных и создать или обратиться к объекту,
не указав схему, Db2 будет использовать идентификатор пользователя, с помощью
которого установлено подключение к базе данных, в качестве имени схемы. Чтобы
задать схему для текущего сеанса работы, можно также воспользоваться оператором
SET SCHEMA.
Создание схемы может быть выполнено явно, путем
вызова оператора CREATE SCHEMA, либо неявно, при первой попытке
создания объекта без указания имени схемы. В последнем случае для успешного
создания схемы пользователю должна быть предоставлено полномочие
IMPLICIT_SCHEMA.
Для большинства видов объектов базы данных могут быть
созданы синонимы, позволяющие обращаться к исходным
объектам через другое имя (возможно, размещённое
в другой схеме). Создание синонимов осуществляется оператором
CREATE SYNONYM / CREATE ALIAS.
Также поддерживается работа с публичными синонимами, которые не привязаны к конкретной схеме.
Обращение к публичным синонимам осуществляется без указания схемы
вне зависимости от установленной текущей схемы сеанса работы.
Создание публичных синонимов осуществляется командой
CREATE PUBLIC SYNONYM / CREATE PUBLIC ALIAS.
Таблицы
Таблица – это собрание связанных данных, логически упорядоченных в столбцах и строках.
Каждая строка таблицы состоит из одинакового набора именованных колонок. Каждой колонке при создании таблицы присваивается тип данных, ограничивающий допустимые значения колонки в строках таблицы (записях базы данных) и определяющий семантику возможных операций над соответствующими значениями (включая сравнение, сортировку, вычислительные операции).
Создание таблицы осуществляется командой CREATE
TABLE, удаление – командой DROP TABLE. Поддерживается
изменение описания таблицы командой ALTER TABLE, включая
добавление и удаление колонок, изменение типов данных
колонок. После выполнения некоторых операций изменения описания таблицы
требуется выполнить её реорганизацию (реструктурировать физическое хранение
таблицы для оптимального доступа к ней) с помощью команды REORG.
Классификация встроенных типов данных Db2, которые могут быть использованы при определении колонок таблицы, приведена на рисунке ниже.
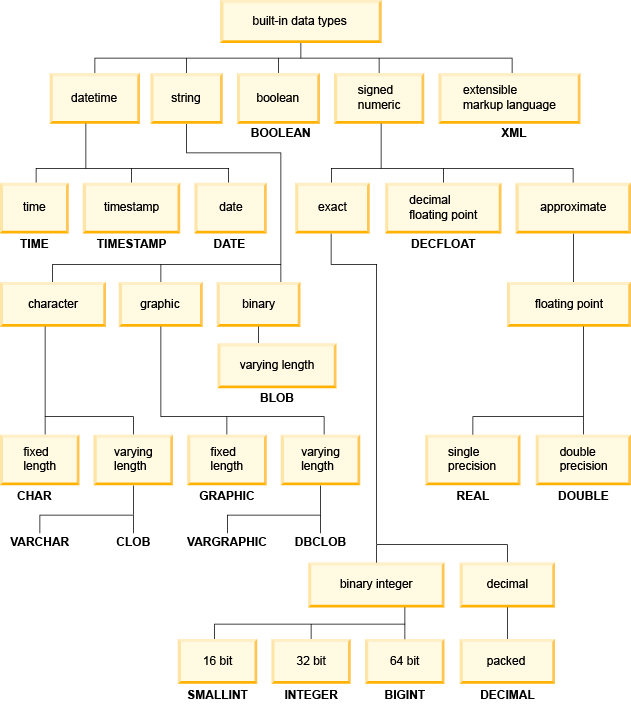
В дополнение к одному из допустимых значений поддерживаемого типа данных, значения колонок могут принимать незаполненное, т.е. пустое (NULL) значение. Возможность для колонки хранить пустые значения определяется при создании таблицы.
Все перечисленные на приведенном выше рисунке типы данных детально описаны в документации. Ниже представлено краткое описание особенностей типов данных, характерных именно для Db2, либо могущих вызвать затруднения при использовании.
При работе со строковыми данными, в отличие от некоторых других
типов СУБД, Db2 различает пустую строку (строку нулевой длины) и
NULL-значение строкового типа. Данная особенность влияет на порядок
поиска (использование предиката равенства вместо выражения IS NULL)
и состав допустимых значений колонок (при запрете
хранения NULL-значений в колонке может быть сохранена пустая строка).
Строковые значения типов GRAPHIC,
VARGRAPHIC и DBCLOB отличаются от других
строковых типов тем, что всегда хранятся в кодировке
UTF-16. При обращении к соответствующим колонкам со стороны
клиентского приложения Db2 обеспечивает
преобразование данных к кодировке, используемой приложением.
Колонки типа DATE (дата) по умолчанию не содержат метки
времени. В режиме совместимости с СУБД Oracle Database в Db2
дополнительно поддерживается хранение атрибутов времени (часы,
минуты, секунды) в колонках DATE.
При необходимости обеспечить эффективную работу с точными
десятичными числами, включающими дробную часть
(например, в финансовых приложениях), целесообразно
использование типа данных DECFLOAT, который комбинирует
точное представление значений типа DECIMAL и
возможности эффективных вычислений над значениями типа FLOAT.
Тип данных BLOB обеспечивает
возможность сохранения в базе данных неструктурированной двоичной информации
(например, изображений или документов офисных
форматов). Значения типа BLOB могут сохраняться вместе
с другими полями записи (если их размер позволяет разместить их достаточно
компактно), либо отдельно, в
специальном объекте хранения. В последнем случае запись содержит ссылку на
хранимое BLOB-значение вместо самого значения. Аналогичным
образом организовано хранение значений типов CLOB и
DBCLOB.
Тип данных XML обеспечивает хранение
в полях таблицы структурированных иерархических документов формата
XML. Для хранимых XML-документов
поддерживаются операции доступа к атрибутам (без необходимости разбора
XML-документа при обращении), индексация отдельных атрибутов
и другие возможности.
В дополнение к встроенным типам данных, Db2 поддерживает работу с пользовательскими типами данных, определяемыми на основе встроенных типов. Работа с пользовательскими типами данных описана в документации.
При создании таблицы существует возможность указать для колонок правила автоматического заполнения их значений. Особым случаем колонок с автоматическим заполнением являются столбцы идентификации – числовые столбцы, автоматически генерирующие уникальное числовое значение для каждой вставляемой строки. Автоматическое заполнение может осуществляться в одном из двух режимов:
GENERATED ALWAYS– значение всегда устанавливается сервером Db2 и не может быть явно установлено приложением;GENERATED BY DEFAULT– значение устанавливается сервером Db2 в том случае, если приложение не указало явно присваиваемое значение при вставке записи.
Также на уровне таблицы могут быть определены ограничения, задающие ограничения на состав значений атрибутов. Поддерживаются следующие виды ограничений:
- первичный ключ (
PRIMARY KEY) – ограничение уникальности на набор колонок, преимущественно используемых для поиска единичной записи, в таблице может быть только один первичный ключ; - ограничение уникальности (
UNIQUE) – дополнительное ограничение уникальности на набор колонок; - внешний ключ (
FOREIGN KEY) – ссылка в виде набора значений колонок, указывающая на комбинацию колонок другой таблицы, для которой определён внешний ключ или ограничение уникальности; - проверка (
CHECK) – логическое условие, ограничивающее возможные значения одной или сразу нескольких колонок в записи.
Механизм ограничений реализует средства автоматического контроля и обеспечения целостности базы данных, включая ссылочную целостность данных (контроль наличия в «родительской» таблице записей, на которые ссылаются через внешние ключи записи «дочерних» таблиц). Грамотное использование ограничений позволяет гарантировать формальную корректность заполнения базы данных и в определённой степени защититься от ошибок приложений и пользователей при корректировке данных.
Поскольку механизм ограничений создает дополнительную вычислительную нагрузку при вводе и корректировке данных, в некоторых случаях от его использования сознательно отказываются, возлагая ответственность за правильное ведение базы данных на приложение. В то же самое время, Db2 использует описания ограничений целостности для определения взаимосвязей между таблицами и подбора наиболее эффективного плана выполнения запросов.
Временные таблицы
Для хранения временных данных приложений в Db2 предусмотрен механизм временных таблиц, предоставляющий полный набор функций работы с табличными данными, но в контексте текущей пользовательской сессии.
Доступ к временным таблицам значительно повышает производительность, поскольку минимизируются либо вовсе не возникают конфликты доступа к системному каталогу, а также не используется блокировка строк, ведение журнала (не обязательно, зависит от режима создания таблицы) и проверка полномочий.
Временные таблицы также поддерживают индексы, т. е. ко
временной таблице можно создать любой стандартный индекс. Для таких таблиц
можно также выполнить сбор статистик (командой RUNSTATS) для получения информации, необходимой
оптимизатору запросов.
Временные таблицы располагаются в пользовательском временном табличном пространстве, которое должно определяться до их создания.
В DB2 существует две основные разновидности временных таблиц:
- объявленные временные таблицы (DGTT – Declared Global Temporary Tables);
- созданные глобальные временные таблицы (CGTT – Created Global Temporary Tables).
Объявленные временные таблицы — это созданные в памяти таблицы, используемые приложением и автоматически отбрасываемые при завершении его работы. Доступ к таким таблицам может получить только то приложение, которое их создало, и они не хранятся ни в одной из таблиц системного каталога Db2.
Каждая объявленная временная таблица имеет схему SESSION;
эту схему необходимо указывать, ссылаясь на временную таблицу в запросах.
Используемый для объявления временных таблиц идентификатор пользователя
будет иметь в этих таблицах все привилегии.
Каждое приложение, объявившее временную таблицу, будет
иметь собственную копию такой таблицы.
Хотя DGTT дают возможность объявить временную таблицу,
определение такой таблицы нельзя совместно использовать в разных подключениях
или сеансах. При запуске каждого сеанса необходимо выполнять оператор
DECLARE GLOBAL TEMPORARY TABLE.
При использовании созданных глобальных временных таблиц (CGTT) определение временной таблицы нужно создать всего один раз, поскольку оно сохраняется в системном каталоге Db2. Это означает, что другие подключения могут воспользоваться определением такой таблицы, а не создавать его снова.
Хотя структуру таблицы CGTT можно использовать сразу, данные разных подключений не зависят друг от друга и пропадают после закрытия подключения.
Индексы
Индекс — это упорядоченный набор ключей, каждый из которых указывает на строку таблицы. Индексы обеспечивают уникальность строк (т.е. реализуют ограничения уникальности, рассмотренные в предыдущем разделе) и повышают производительность.
Ниже описаны некоторые характеристики, которые можно определить для индексов:
- индексы могут строиться по возрастанию или по убыванию значений колонок;
- ключи индексов могут быть уникальными или неуникальными;
- индексы могут строиться по нескольким столбцам (такие индексы называют комбинированными);
- индексы могут строиться как на основе значений колонок, так и в соответствии со значениями выражений над колонками таблицы (expression-based index);
- если табличные данные отсортированы в соответствии с последовательностью записей индекса, этот индекс называется группирующим, или кластеризующим (clustering index).
Создание индексов обеспечивается оператором
CREATE INDEX, удаление – оператором DROP INDEX.
При создании индекса указывается его тип (уникальный или неуникальный)
и состав колонок для построения индекса.
В Db2 предусмотрены инструменты, обеспечивающие автоматизированный подбор индексов для оптимизации выполнения запросов. Наиболее удобно работа с данными инструментами организована в IBM Data Studio.
Последовательности
Хотя объекты последовательностей не зависят от таблиц, они функционируют аналогично столбцам идентификации и обеспечивают генерацию уникальных числовых последовательностей. Разница между последовательностями и столбцами идентификации заключается в том, что столбцы идентификации генерируют уникальные числа строго в указанной колонке таблицы, тогда как объекты последовательностей могут использоваться для генерации последовательных числовых значений, логика использования которых определяется приложением.
Создание последовательностей обеспечивается командой
CREATE SEQUENCE, обращение к очередному и текущему
полученному значениям осуществляется с помощью операторов
NEXT VALUE FOR и PREVIOUS VALUE FOR. Для совместимости с СУБД
Oracle Database также поддерживается синтаксис обращения
к значениям последовательности через
псевдо-колонки NEXTVAL и CURRVAL.
## Представления
Представление – это отображение данных в таблицах. Данные для представлений не хранятся отдельно, они отбираются при обращении к представлению в запросе. Поддерживаются вложенные представления, т. е. представления, созданные на основе других представлений.
Создание представлений осуществляется командой
CREATE VIEW, удаление – командой DROP VIEW. Для
облегчения обновления (замены) представлений предусмотрен синтаксис
CREATE OR REPLACE VIEW, который обеспечивает создание нового
представления (если его еще не существует) либо замену существующего
представления на новое определение (если представление с указанным именем уже
было ранее создано).
Триггеры
Триггер — это объект, который автоматически выполняет операцию с таблицей или представлением. Определенное действие с объектом, для которого определен триггер, вызывает запуск триггера. Обычно триггер не считается объектом приложения; соответственно, обычно триггеры создаются не разработчиками, а администраторами баз данных.
Хранимые процедуры и функции
Хранимые процедуры – это объекты базы данных, содержащие
операторы SQL и бизнес-логику. Хранение части логики приложения в базе данных
повышает производительность, поскольку сокращается объем трафика между
приложением и базой данных. Кроме того, хранимые процедуры предоставляют
централизованное местоположение для хранения программного кода, и,
соответственно, другие приложения могут воспользоваться
теми же хранимыми процедурами. Для вызова хранимой процедуры используется
оператор CALL.
Пользовательские функции (UDF, User Defined
Functions) – это объекты базы данных, позволяющий пользователям расширить
язык SQL собственной логикой. Функция всегда возвращает значение или значения,
обычно как результат включенной в функцию бизнес-логики. Чтобы вызвать функцию,
используйте её в составе оператора SQL, например, в операторе VALUES,
SELECT или INSERT.
В Db2 хранимые процедуры и пользовательские функции можно разрабатывать на нескольких языках программирования, среди которых PL/SQL, SQL PL, Java, C, C++, COBOL.
Системный каталог
Одним из базовых информационных ресурсов СУБД является системный каталог, хранящий и предоставляющий доступ к информации о структуре базы данных, включая:
- описание таблиц, колонок и индексов;
- описание и текст представлений, триггеров и хранимых процедур;
- сведения о табличных пространствах и контейнерах для хранения данных;
- установленные полномочия по доступу к объектам базы данных;
- другую метаинформацию базы данных.
Обращение к системному каталогу требуется при решении многих задач, включая автоматизацию задач администрирования и обслуживания баз данных, разработку приложений и многое другое.
Наиболее часто используются следующие таблицы (в действительности, представления), входящие в состав системного каталога:
SYSCAT.SCHEMAS– описание схем базы данных;SYSCAT.TABLES– описание таблиц базы данных;SYSCAT.COLUMNS– описание колонок таблиц;SYSCAT.INDEXES– описание индексов.
Детальное описание и состав колонок для перечисленных выше и других таблиц системного каталога Db2 приведено в документации.